本次会议围绕文件系统、磁盘性能提升以及可执行程序加载等多个主题展开讨论,详细讲解了相关知识和技术,分析了存在的问题并提出了解决方案,内容如下:
文件系统知识回顾

文件系统存储内容
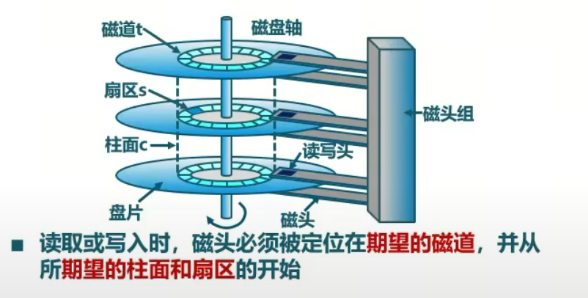
磁盘上组织成的数据
-
文件和文件夹:文件系统主要存储两类东西,文件是将扇区组织成自由长度的结构,可采用链表、树、哈希表等形式;文件夹是对文件的分类索引,本身也是一种文件。
-
磁盘存储结构:假设每个文件是一个链表,整个磁盘上就存储着各式各样的链表,找到链表的表头即可串联起后面的所有内容。
文件系统的技巧
-
树根存储:为节省搜索时间,文件系统将树根存储在磁盘的特定位置。磁盘又大又慢。数据结构的课中,没有父节点。
-
打开文件表:操作系统缓存了一张打开文件表,用于记录文件链表表头在磁盘中的位置,以减少查找时间。
打开文件表的问题及解决方法
-
表的上限:打开文件表有上限,早期操作系统支持 256 或 1024 个文件,现在可根据内存大小扩展。
-
表满处理:当表满时,可采用扔掉长时间不用的文件句柄的方法,同时需要统计文件句柄的使用频率。
-
重复打开文件:重复打开同一个文件会创建多个打开表项,为避免这种情况,可复用已有的数据。open的返回值 unsigned int.
-
文件指针独立性:每个进程可以有自己独立的文件指针,操作系统设计者可决定进程是否允许有多个文件指针。fd记录着读到了哪个字节。
文件系统的锁和缓存
-
文件锁:文件系统上的锁是建议锁,不是强制锁,Windows 和 Linux 系统在文件删除时的提示机制不同。u盘的弹出,直接拔掉不会出错
-
文件缓存:可在文件系统的内存中做 cache,将已读数据存储下来,以提高读取速度,但会出现 cache的毛病浮现写回延迟和读写放大等问题。
新存储介质 NVM
-
文件系统接口:即使有了新的存储介质 NVM,字节型接口 也需要为其重新建立一套文件系统接口,以实现对现有二进制系统的兼容。之前的文件系统建立在磁盘 上扇区 磁道。
-
操作系统开发困难:在成熟的操作系统领域开发新系统困难,因为需要保留原有二进制程序的系统调用接口,否则应用程序需要重新适配。
磁盘性能提升
磁盘访问时间分析
值得注意的时间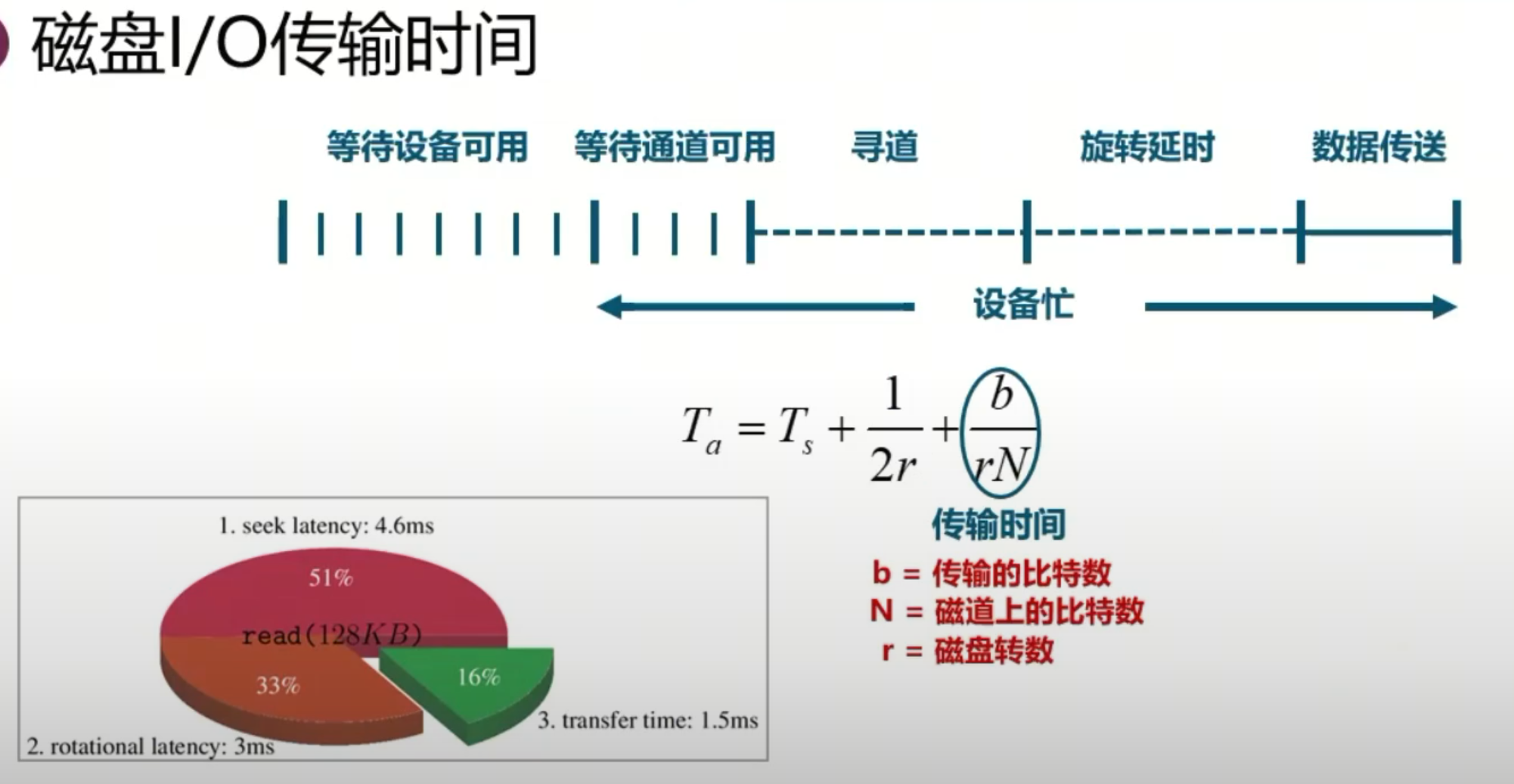
-
寻道时间:磁头移动到目标磁道上空所需的时间,是影响磁盘性能的主要因素。
-
旋转延迟:磁头到达目标磁道上空后,等待目标扇区旋转到磁头下方所需的时间,平均约为半圈的旋转时间。概率。
-
数据传输时间:将目标扇区的数据传输到内存所需的时间,由用户读取的数据量决定。
-
对大头下手,解决主要问题《来自组成原理的概念。所以就是寻道时间了。
磁道调度方法
提高磁盘对你的响应速率。读写请求。磁道管理。
先入先出(FIFO):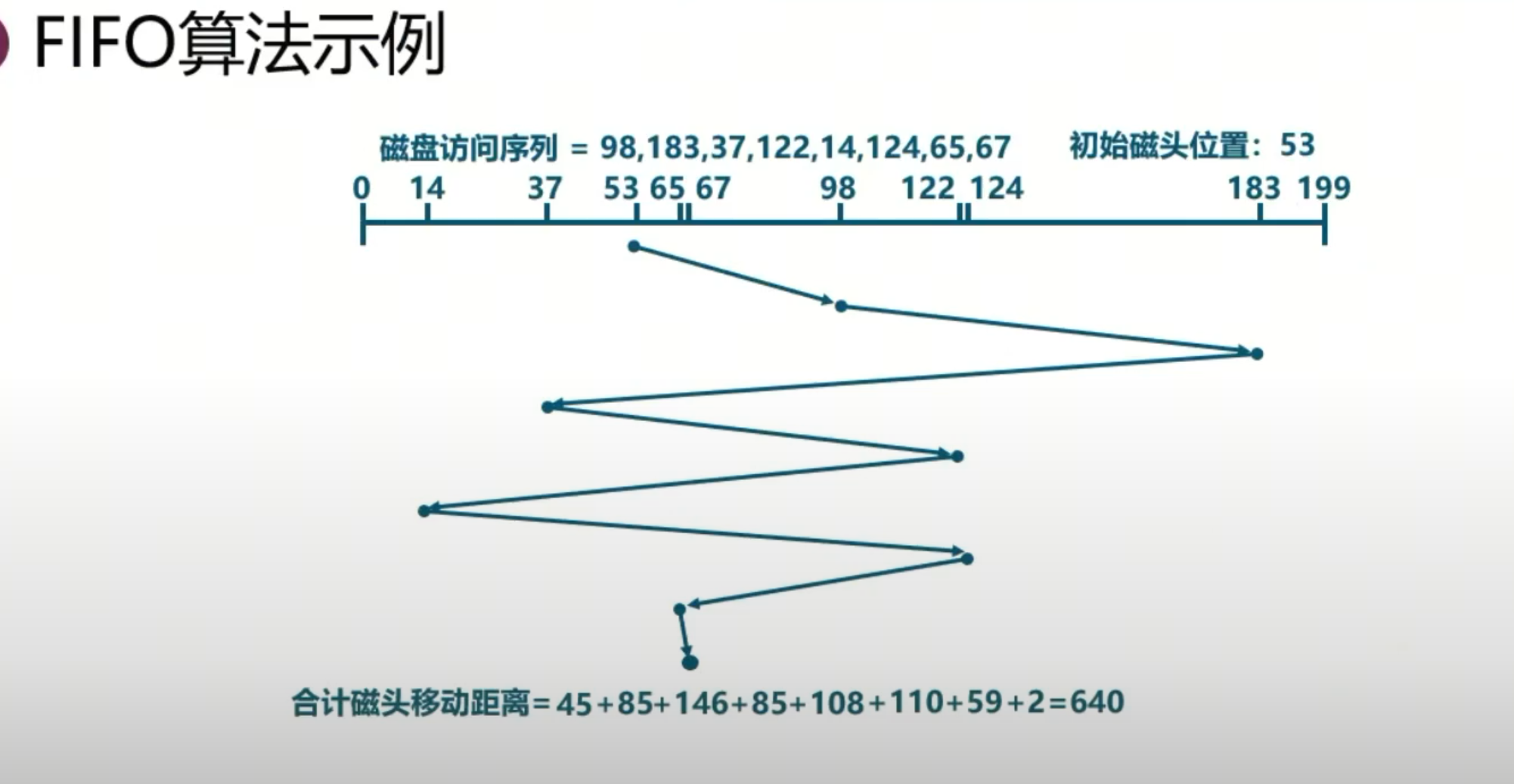
最简单(好处)的调度方法,但磁头移动频繁,效率较低。来回移动,机械行为。物理上的加速减速。53到98。掉头不希望看到。
短路径优先(SSTF):经典方法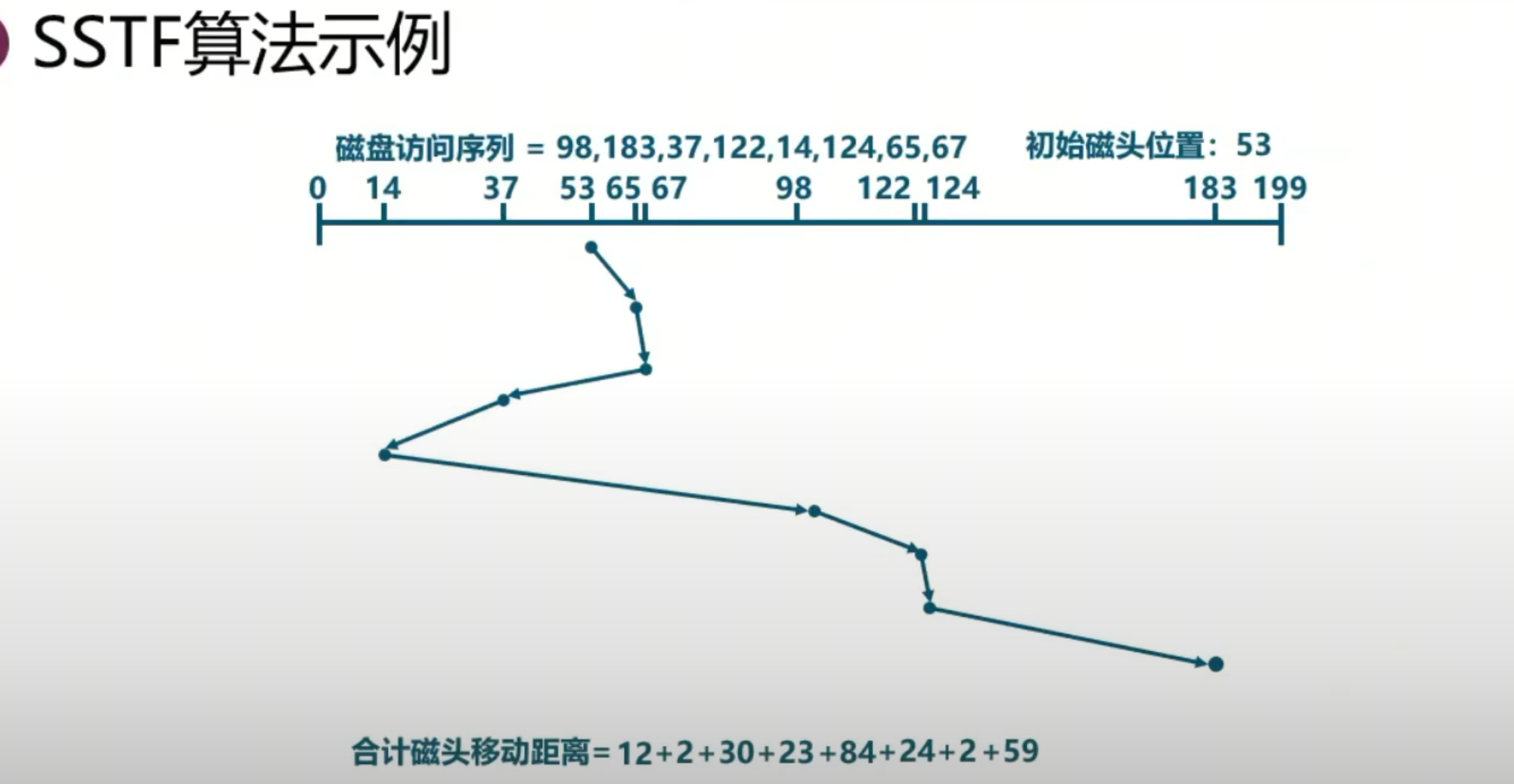
选择距离当前磁头位置最近的磁道进行访问,可减少磁头移动距离,但可能导致磁头黏滞现象。 问题:来回移动,一堆动态到达的请求的时候。把磁头黏在一个地方。
扫描算法(电梯算法):最经常使用
更不愿意看到掉头,机械损伤
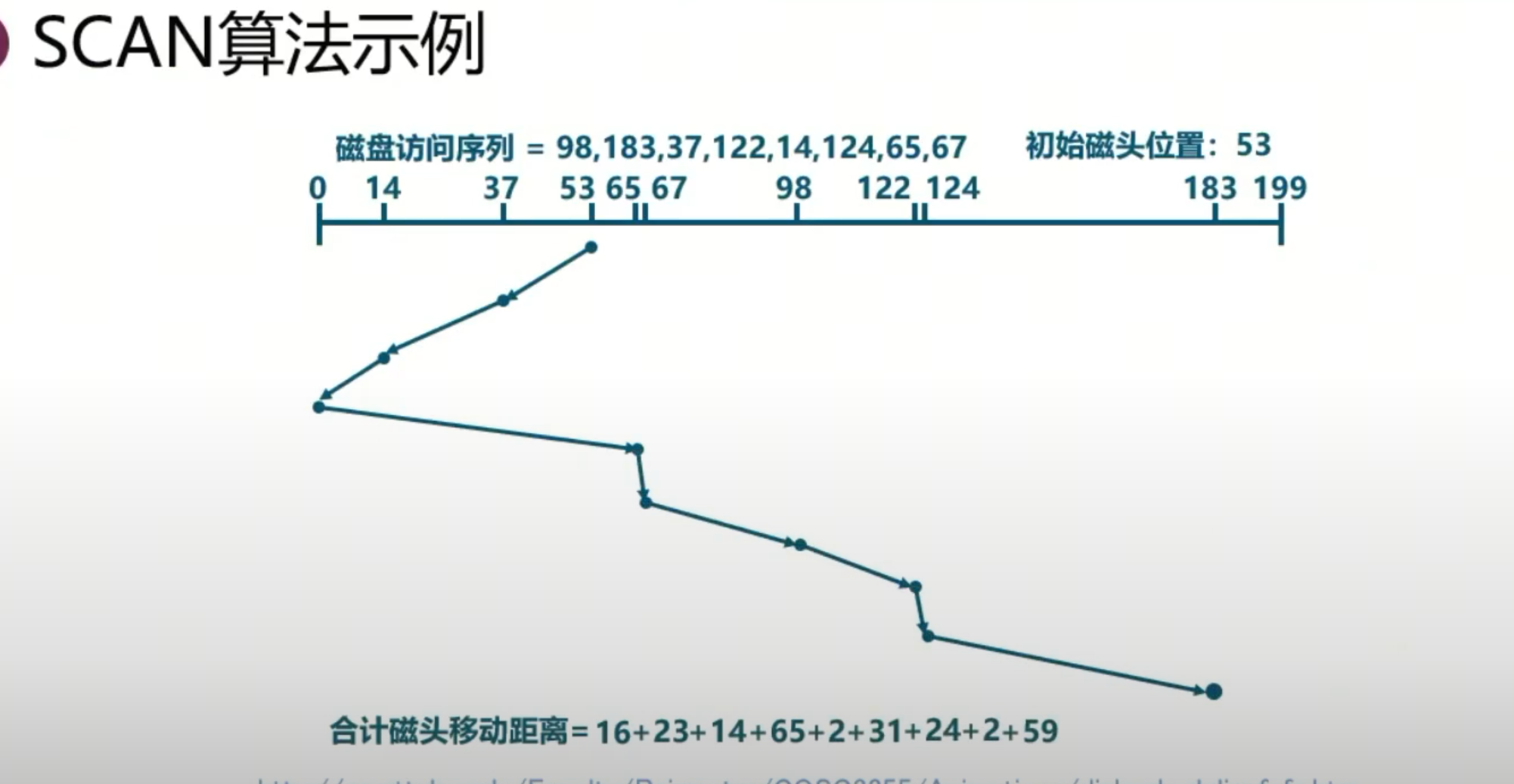
磁头先沿着一个方向移动,处理完该方向上的所有请求后再掉头处理另一个方向的请求,可减少磁头掉头次数。
循环扫描法:电梯调度的改进
只在一个方向上完成读写请求,到达最大磁道号后直接将磁头抬起到 0 号磁道,再进行下一轮循环。而不是慢慢走回来。
n 步扫描法:
一次接收固定数量的请求,按照特定方法处理,处理过程中到来的新请求放入另一个队列等待,采用双缓冲机制。
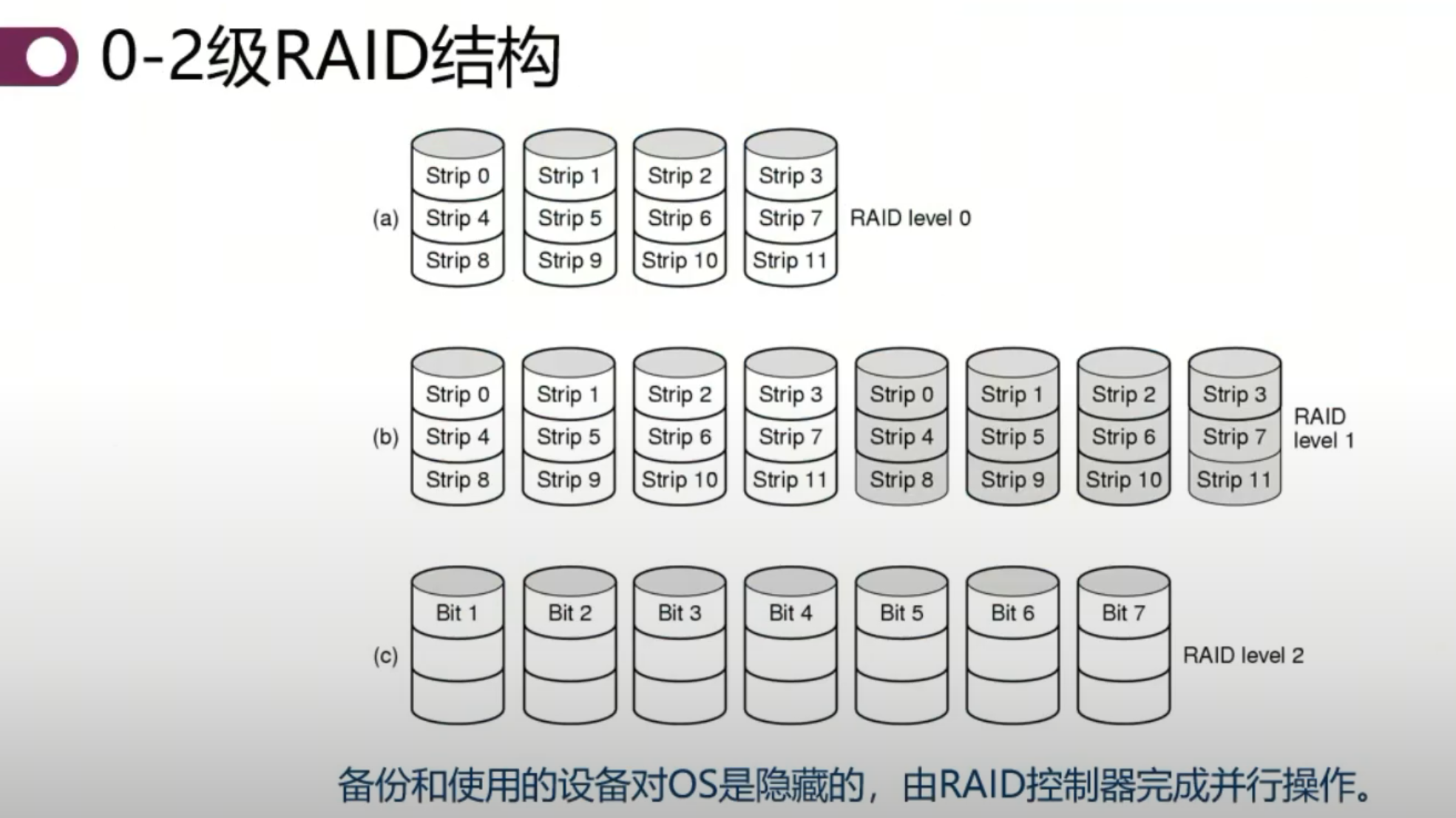
RAID 系统 redundant array of inexpensive disks
 1秒100兆磁盘,内存1秒几十个g,放1000个硬盘,一起启动,1秒钟传100g,磁盘速度线性叠加。
1秒100兆磁盘,内存1秒几十个g,放1000个硬盘,一起启动,1秒钟传100g,磁盘速度线性叠加。
廉价磁盘的冗余阵列。
-
RAID 0:将用户数据切成块,均匀分布在多个磁盘上,实现数据的并行读写,提高磁盘读写速度。条带化。一个人读可,第二个人就不可了。条带化
-
RAID 1:照四块盘的样子再做四块盘。对 RAID 0 的数据进行原样复制,提供数据副本,提高数据的可靠性和读写带宽。2 个人想一起读。
-
RAID 2:将数据拆成比特存储在多个磁盘上,但由于磁盘操作效率低,毫秒级寻道。该方案被废弃。 重要前提:磁盘是廉价的
-
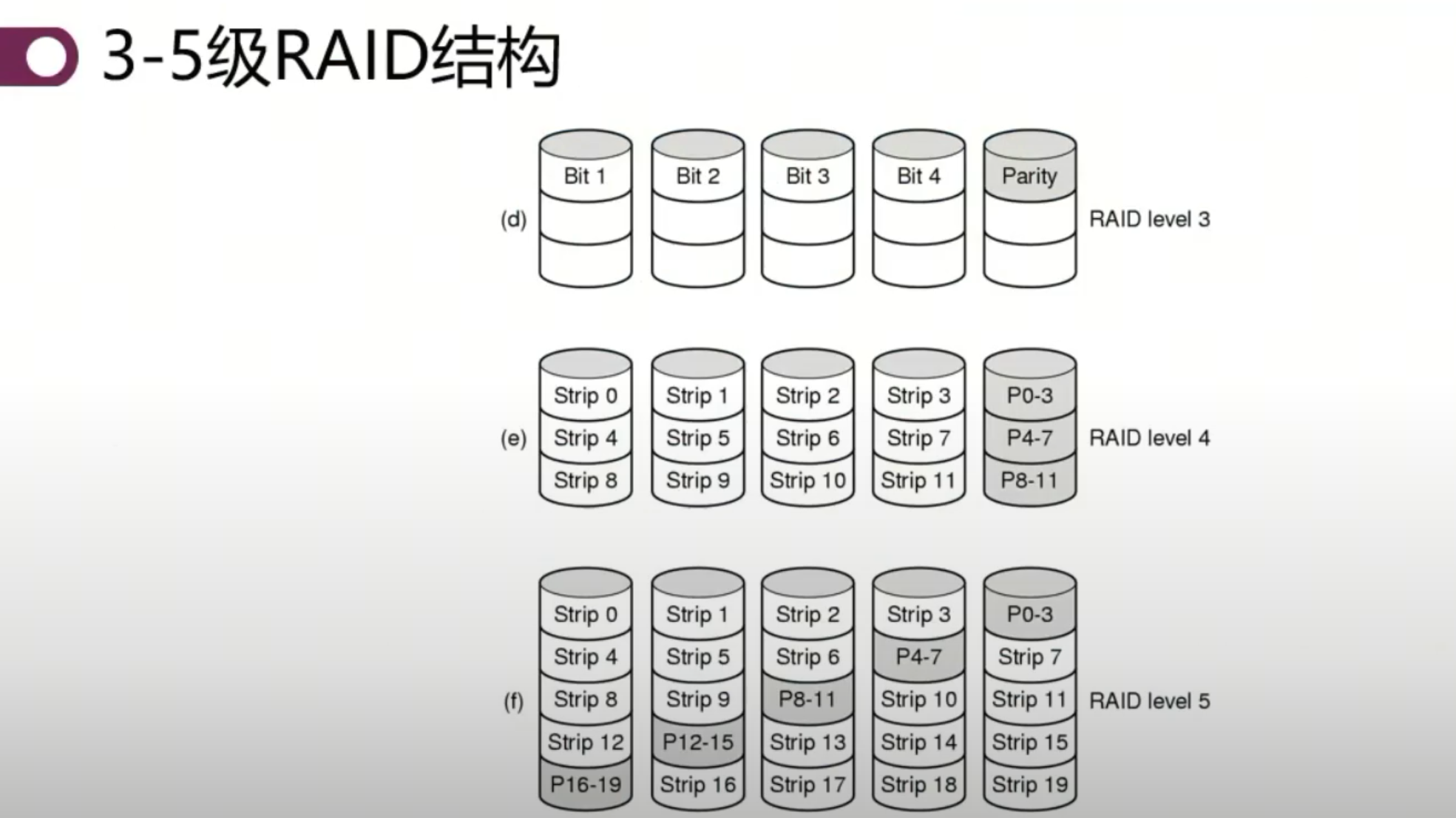
RAID 3:通过数学运算减少数据存储冲突,用计算换存储,但按比特操作无意义。
-
RAID 4:将条带化数据做异或运算放在最后一块盘上,计算代替存储可实现磁盘损坏修复和加速,但校验盘读写频繁,岁让上千万次读写,容易损坏。
-
RAID 5:将校验和均匀分布在各个盘片上,负载均衡,可抵御一块盘片坏掉,是比较完善的方案。
-
RAID 5 + 1:结合 RAID 5 和 RAID 1 的优点,提高数据的可靠性和读写效率。两块盘。 这几个策略是并行的 不是迭代的
文件系统的性能思考
- os 喜欢做顺序的读写以改进性能,沿着盘片转动的方向
- 但是用户按照什么方式读写磁盘?
可执行程序加载
可执行程序被存在磁盘上的时候是怎么样被读走的
可执行程序的存储和读取
-
谁是可执行程序的写者?谁往磁盘里写,编译器或者下载器。二进制可执行程序几乎不修改。病毒。。。
-
二进制程序的格式是编译器开发者和操作系统设计者两者约定。约定怎么存怎么读。保证健壮性和扩展性。
-
文件头:可执行程序的文件头用于标识文件类型,Linux 系统通过 ELF header 比对确定可执行文件,Windows 系统通过文件扩展名标识。

-
程序头表:程序头表记录了程序的虚拟地址空间排布,包括数据的起始位置、长度、权限等信息。
-
section header 方便编译器知道数据放到哪里去了。text .segment 运行,section 编译
-
虚拟地址空间:编译器和操作系统约定了可执行程序的地址空间记录和读取方式,程序执行时根据程序头表构造虚拟地址空间。成员变量memsz filesz,压缩时不同,
传统 read 操作的问题
-
启动慢:对于大型可执行程序,使用 read 操作将所有数据加载到内存中会导致启动过程漫长。
-
内存消耗大:由于操作系统的缓存机制,使用 read 操作读取数据会在内存中产生两份副本,缓存一份。增加内存消耗。
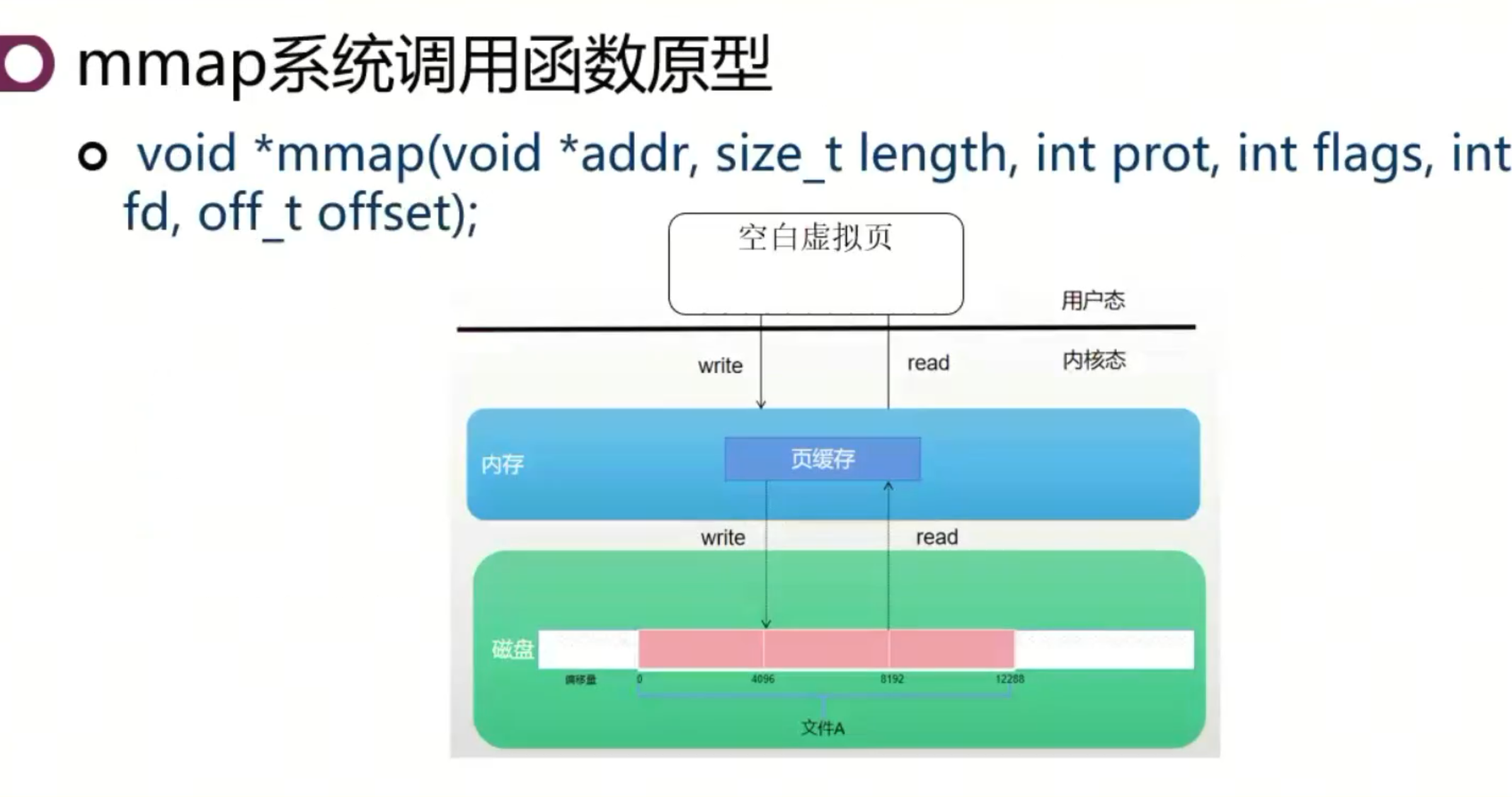
MMAP 函数的应用
对一个进程虚拟地址空间的一个操作,是一个系统调用。操作系统为你提供。

-
原理:制造一个合法的空洞。MMAP 函数在进程的虚拟地址空间中创建一个映射,将对该地址空间的访问转换为对文件的访问,实现按需加载。 缺页+读磁盘
-
优点:MMAP 函数避免了数据的重复加载,减少了内存占用,提高了程序启动速度。
-
缓存机制:为解决 MMAP 操作的慢速问题,可在内核中创建一个配置 cache,将已读数据存储在 cache 中,下次访问时直接从 cache 中读取。磁盘某个特定位置的读写。
-
做了的操作:1. 在用户空间掏了一个洞,没有真正意义上的分配物理内存;2. 这块物理内存的读或写会被操作系统翻译成对文件的读或写 3. 由于对于内存的读写太慢。内核里申请了一块数据的缓冲区,再下一次的读或者写直接在这个区域里完成。
MMAP 操作的权限问题
-
页的权限标识:MMAP 操作创建的页同时属于内核和用户空间,不同权限的地址访问该页会有不同的结果。
-
数据安全:物理内存上的数据没有权限标识和数据保护,攻击者可通过液氮冻结 DRAM 数据的方式读取内存中的数据。
后面没声音了呜呜~