上一节课 使用antlr 4生成 词法分析器;
今天 手写
4类:数字 关键字 id 关系运算符
 - 数字最复杂 需要考虑 小数点 科学计数法 允许有前导0 。三个部分
- 词法分析与语法分析文件分开写的原因:大家的词法可能是一样的,java 和cpp.表示变量 数字;语法不一样
- 数字最复杂 需要考虑 小数点 科学计数法 允许有前导0 。三个部分
- 词法分析与语法分析文件分开写的原因:大家的词法可能是一样的,java 和cpp.表示变量 数字;语法不一样
- 数字进一步分类:
INT: DIGITS ; REAL: DIGITS('.' DIGITS)? ; SCI: DIGITS('.' DIGITS)? ([eE][+-]? DIGITS)? ; - 使用两个域来表示一个token,类型与内容
public enum TokenType{
//group 0
EOF,
UNKNOWN,
//group 1
//只需看当前第一个字符 就可以判断进入哪个分支 lookhead = (LA(1)):即向前看的字符等于1
DOT,POS,NEG,
IF,ELSE,
ID,
INT,
ws, //空白符
//group2 关系运算符
//=,<>,<,<=,>,>=
// lookhead = (La(2))需要。。。 两个嵌套的语句
EQ,NE,LT,LE,BT,BE,
//group3
//向前看不确定字符 循环结构 whilearbitrary LA
REAL,
SCI,
}
仓库 antlr4 ggrammars-v4 可以查看各种语言的语法分析和词法分析
正则表达式
id:字母开头的字母/数字串。id 定义了一个集合,我们称之为语言。语言中的每个元素被称之为串(标识符)。 语言是串的集合 可以集合操作构造新的语言,
| L 和M并 | 得到更大的语言/集合 |
| 连接 | |
| 克林闭包 | L* |
| 正闭包 | L+ |
L*(L+)构造无穷集合/语言
id:L(LUD)* L:字母;D:数字
 表达式本身是语法概念,只描述是怎么构成的,具体的含义是语义所关心的事情。
记不住优先级的话 疯狂加括号
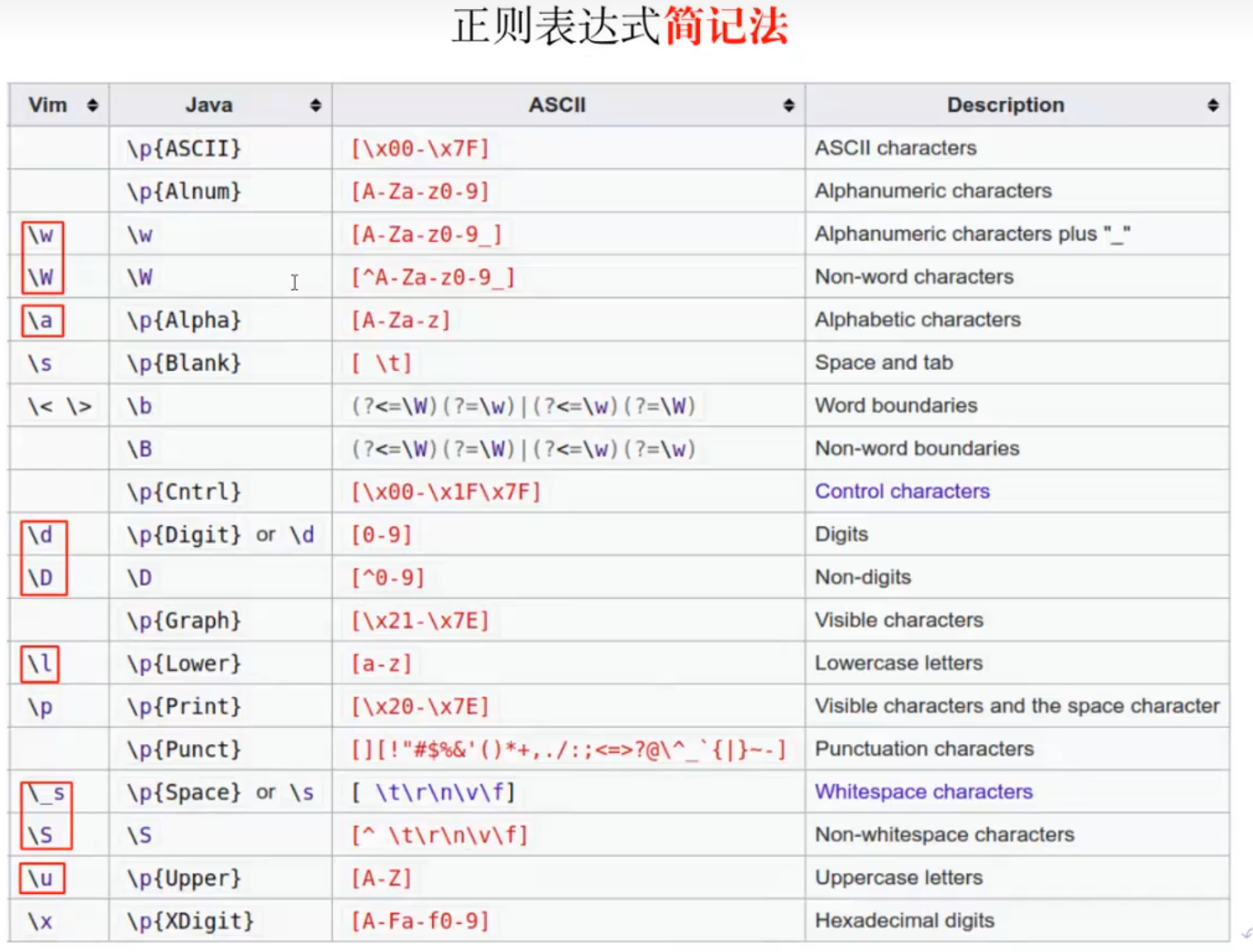
正则表达式简记法
表达式本身是语法概念,只描述是怎么构成的,具体的含义是语义所关心的事情。
记不住优先级的话 疯狂加括号
正则表达式简记法
(0|1(01*0)*1)*匹配三的倍数,隔两个匹配一个 为之一振 待查
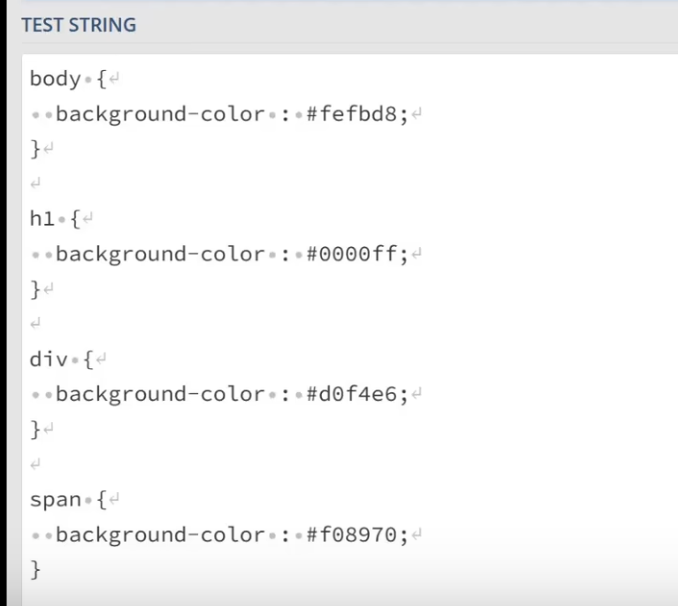
 写一个正则表达式匹配所有的颜色html中 六位十六进制数
写一个正则表达式匹配所有的颜色html中 六位十六进制数
数字的可能性:[0-9a-fA-f] 恰好是六位:[0-9a-fA-f]{6}
日期的格式 3/8/23;3-8-2023;2/2/2;03-08-2023
分为三部分 第一部分是数字 一位或者两位: \d{1,2} 中间是分隔符 要么是-或者\使用转义符号\d{1,2}[-/] 第二部分与第一部分相同:\d{1,2} 第三部分:\d{2,4}
 订单号金额 匹配>=100美元 小数点后保留两位
识别美元符号 :
订单号金额 匹配>=100美元 小数点后保留两位
识别美元符号 :\$
至少三位数字 :\$d{3,}
小数点 转义 :\$d{3,}\.
小数点后两位:\$d{3,}\.d(2)
the cat scattered his food all over the room.
匹配cat 替换掉它dog 注意到scatter
\bcat\b boundary不相匹配到单词中间部分
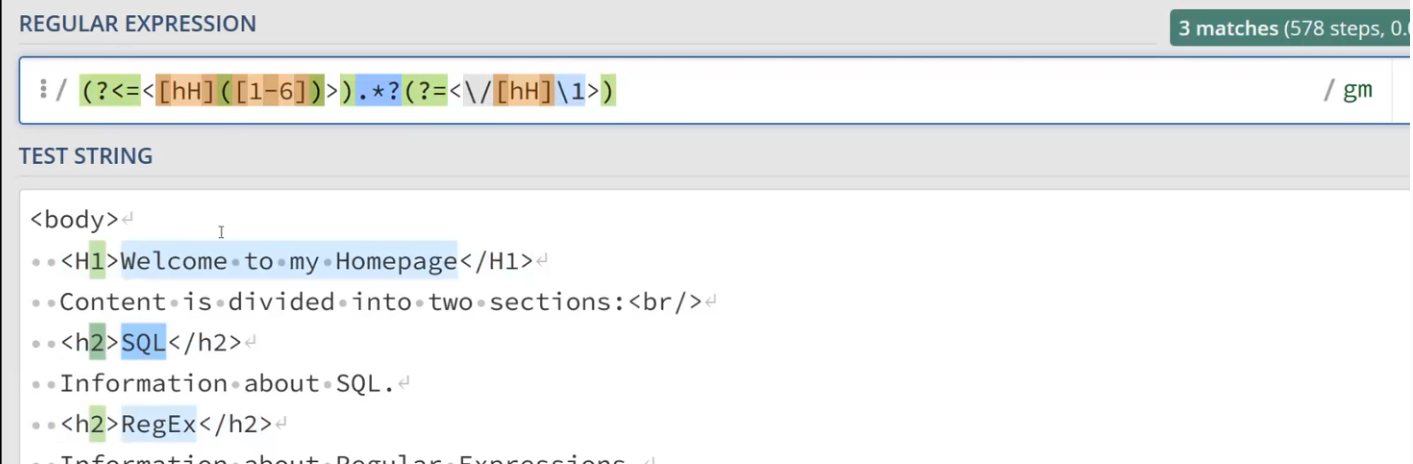
匹配所有的head
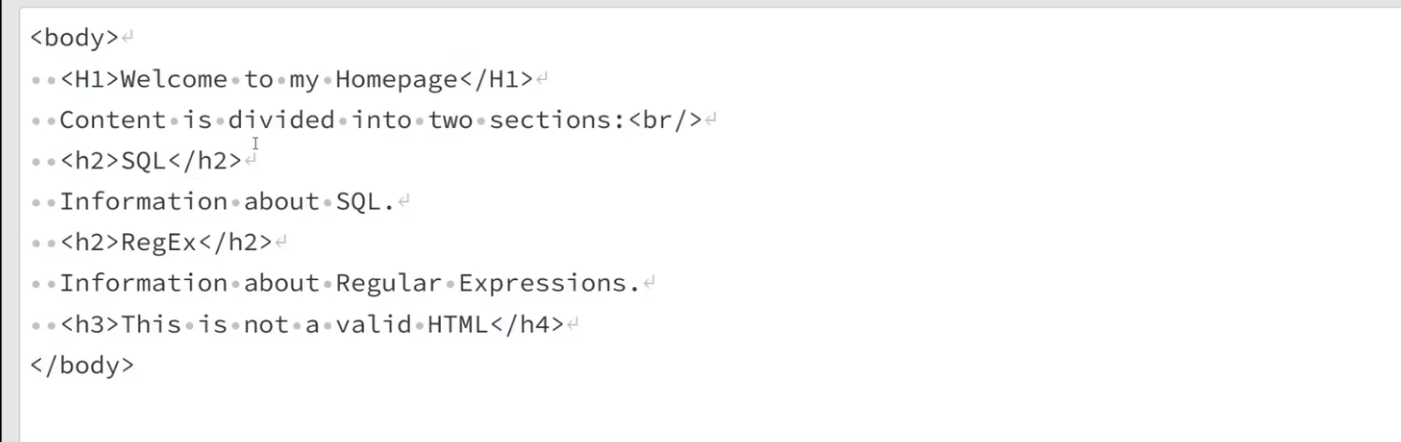
<[hH][1-6]>.*?<\/[hH][1-6]>
中间的文字匹配 待查 如何表达后面的对前面的依赖关系?反向引用
子表达式使用括号
<[hH]([1-6])>.*?<\/[hH]\1>
另一个例子:
向后看 返回结果却只返回前面的内容;向前看 类似
首先把向后看的r放到子表达式里,
<[hH]([1-6])>.*?(?=<\/[hH]\1>)问一问后面的表达式是否等于它
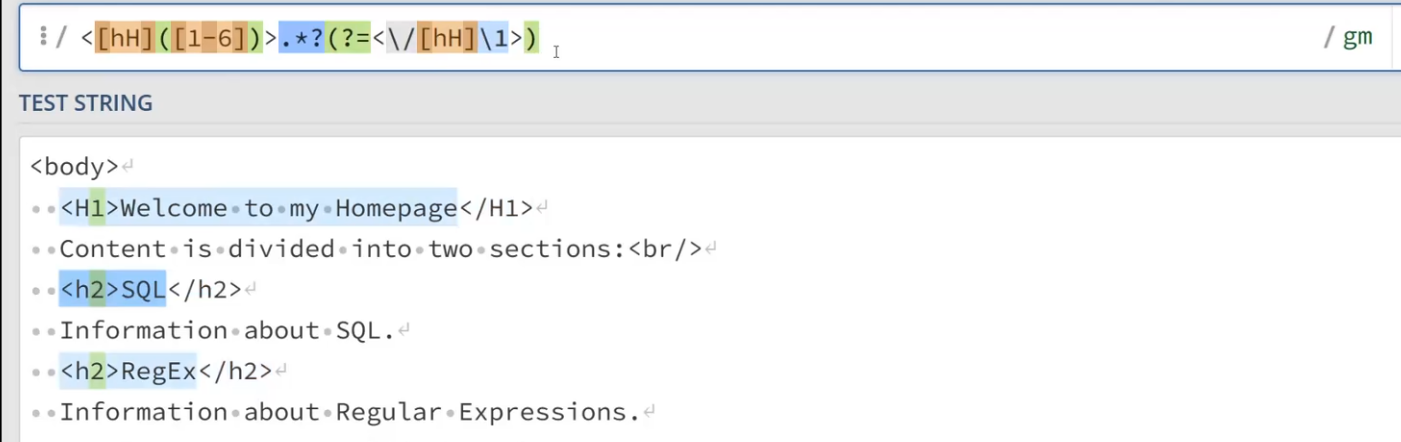 向前看 ?⇐
向前看 ?⇐
在源码中大部分都集中在识别数字上
 识别三类数字 int real 科学计数法
识别三类数字 int real 科学计数法
扫描 识别 若不满足假设回退 向前看。
向前看 向前走 调整状态 记录关键点 伺机回头
碰到小数点 很可能是实数;碰到大E,很可能是浮点数;
nextToken()
while(nextToken())
public void testNextToken(){
Token token=lexer.nextToken();
while(Token!=Token.EOF){
if(token != Token.WS){
System.out.println(token);
}
token=lexer.nextToken();
}
}核心:Token nextToken() Token类两部分组成:类型与具体涵义(string)
对于组1,要想识别出来 只需要看自己 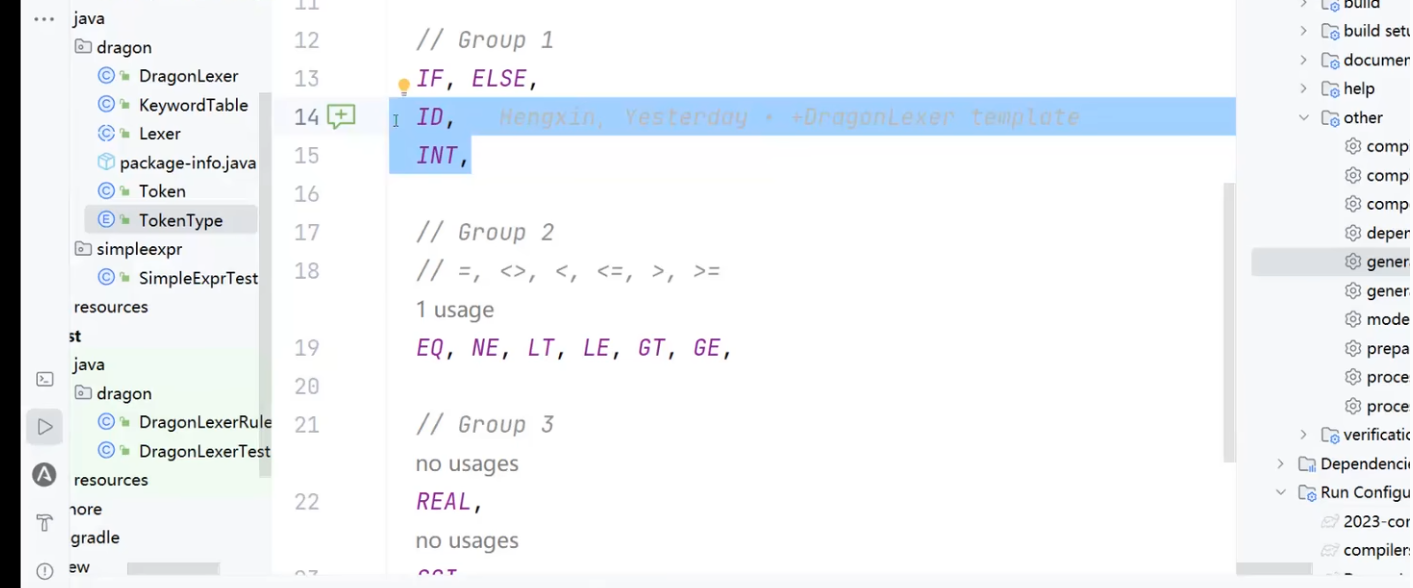 lookahead=1 LA(1)
lookahead=1 LA(1)
对于组3 需要看任意多个 需要用到循环