以阶乘程序为例来探究工作流程
#include<iostream>
using namespace std;
int main(){
int i,n,f;
cin>> n;
i=2;
f=1;
while(i<=n){
f=f*i;
i=i+1;
}
cout<<f<<endl;
return 0;
}预处理
- 正式编译之前的步骤,文本处理,包含的工作:头文件包含:将指定的头文件内容插入到#include指令的位置 ;宏的替换:替换成其定义的内容;去掉注释:将所有注释替换为空格;处理条件编译#ifdef/#else/#endif:根据条件判断,保留或删除部分代码;得到的另一个cpp程序通常是以.ii作为文件扩展名,与c的i对比。
- gcc是如何找到头文件的?
- expand:展开
- gcc -E factorial.cpp —verbose > /dev/null查看详细工作流程
--verbose的输出是发送到标准错误,而> /dev/null只重定向标准输出
- gcc实际上是通过调用另一个程序cc1plus来预处理的。
编译
词法分析
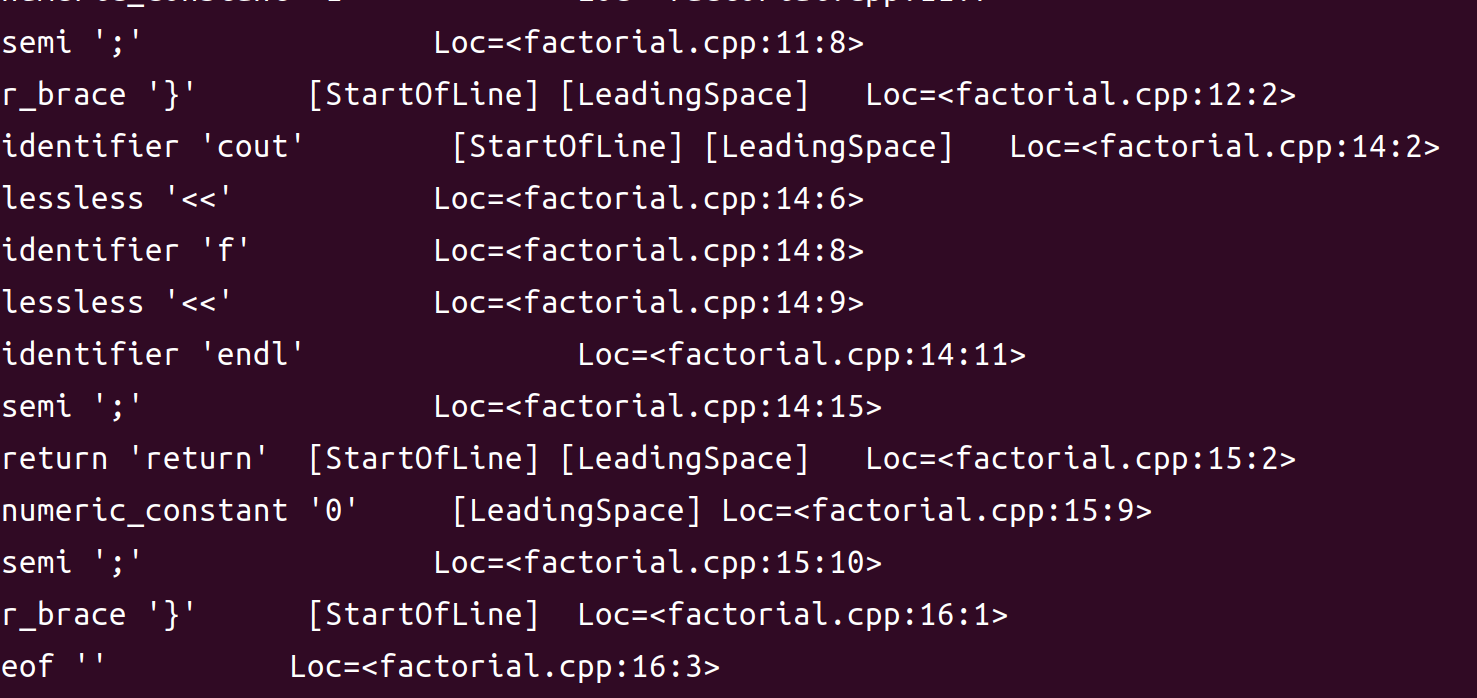
- 词法分析的工作是识别并且记录源文件中的每一个token 包括标识符,关键字,常数,字符串,左大小括号,右大小括号,运算符,分号等等。
- 两种命令 一种是利用之前生成的预处理文件来进行词法分析
clang++ -fsyntax-only -Xclang -dump-tokens factorial.ii; 另一种是从源文件开始预处理加词法分析`clang++ -E -Xclang -dump-tokens factorial.cpp - 最后的结果产生token流,每一行内容包括token类型,对应的字符串,标志,位置<文件名:行:列>
 `
`
语法分析
- 该部分的工作是按照cpp语言的语法将识别出来的token组织成树状结构,从而梳理出源程序的层次结构。文件→函数→语句→表达式→变量
- 在clang中词法分析器是由lexer类实现的
- `clang++ -Xclang -ast-dump -fsyntax-only factorial.cpp
对于生成的语法分析树的理解
- 一个functiondecl由compoundstmt组成,即一个大括号。main函数由一个{}括起来的复合语句。整段树描述的是 main 函数内部的语句
- 竖线表示是子节点,而` 表示是最后的子节点。

- 首先是变量的声明语法,然后是c++操作符函数调用;赋值语句为二元运算的语法,while语句的条件表达式语法是二元运算,这里的i和n做了隐式的类型转换,使得i和n从左值变成了右值,左值代表的是他们在内存中的一个位置,而⇐运算需要他们存储的实际值来进行数值比较,即右值。
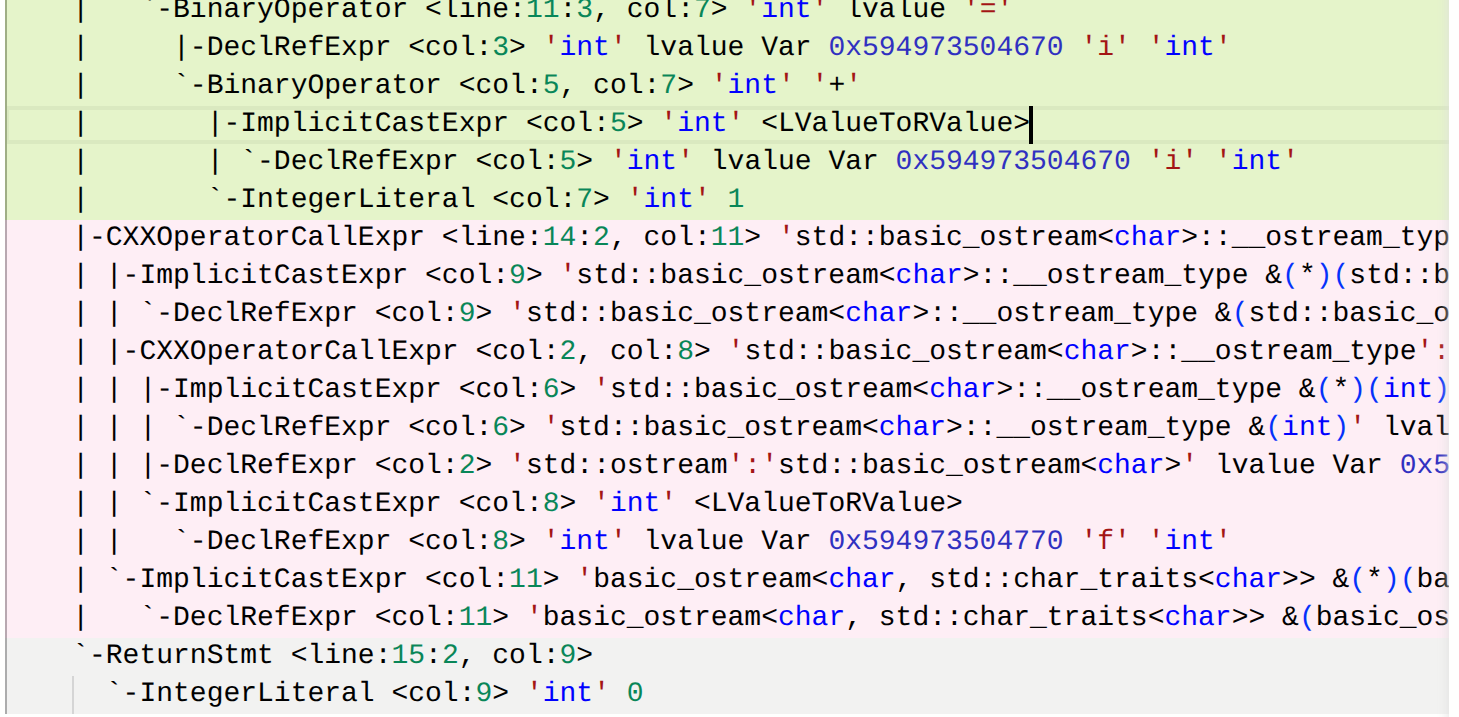
- 对于
cout<<f<<endl;的语法分析为,调用了操作符重载的函数 - 多个
<<是从左到右依次调用的。最外层的c++operatorcallexpr调用<<,左参数是cout<<f(嵌套的操作符调用),右参数是endl(函数模板) - return也是一个语句。
- 编译器把函数名转换成函数指针:<<,endl等
语义分析
该阶段的工作是使用语法树和符号表中的信息来检查源程序是否和语言定义的语义一致。它同时也收集类型信息,并把这些信息存放在语法树或符号表中,所以语义分析的一个重要部分是类型检查。编译器检查每个运算符是否具有匹配的运算分量。比如 在很多程序设计语言中要求数组下标必须是整数。如果用浮点数作为数组下标,编译器就必须报告错误。语法分析只是对代码的表象进行分析,语义分析则是对表象之外的部分进行分析。
中间代码生成
在源程序的语法分析和语义分析完成之后,编译器会生成一个明确的低级或类机器语言的中间表示。它具有易于生成且能够被轻松地翻译为目标机器上的语言。
不同的编译器可能会采用不同的中间代码, 例如clang使用的中间代码叫LLVM IR, gcc使用的中间代码叫GIMPLE.
使用命令clang++ -S -emit-llvm factorial.cpp生成后缀为ll(low level)的文件
编译优化
在这一过程中编译器将生成的中间代码转换为更加简洁、高效且语义不变的中间代码。编译器设计优化管道与管道内的各个优化模块,通过依次执行优化管道里的每个模块,消除中间代码内部的冗余代码,改变代码的执行顺序,降低执行过程中的程序开销,并将代码转化成更加便于目标代码相关优化的形式。
首先,观察所有pass的效果,先添加-disable-O0-optnone选项重新生成中间代码,确保可以优化。使用命令
llc -print-before-all -print-after-all a.ll > a.log 2>&1
查看log文件,经过了306个pass
对比pass前后的代码发现发现IR层面并没有做明显的优化。因为llc的主要目标是代码生成而非IR本身的优化。所以我们使用opt工具来尝试优化。 使用特定的pass
- 内存访问优化:将堆栈变量提升到寄存器
当我们执行命令
opt -passes='mem2reg' -S factorial_optimizable.ll -o factorial_mem2reg.ll,该优化减少了从内存读取数据的指令数量,从原来的11条变成了1条
- 指令局部优化:执行命令
opt -passes='instcombine' -S factorial_mem2reg.ll -o factorial_final_simple.ll,该pass能够执行代数化简、合并冗余指令,进一步提升代码质量。 比较发现有两个改动,首先是循环退出条件的改变,优化前的代码如下:
优化之后变成了%5 = icmp sle i32 %.01, %4 ; %5 = (i <= n) br i1 %5, label %6, label %9 ; 如果 i <= n 为真,跳转到循环体,否则退出
该pass将小于等于时循环的条件改成了大于时退出,逻辑上是等价的,这种更改是符合大多数编译器规定的格式。(满足某个条件时退出) 第二个改动是将加法指令添加nuw(no unsigned wrap)标记。 优化前%.not = icmp sgt i32 %.01, %4 ; %.not = (i > n) br i1 %.not, label %8, label %5 ; 如果 i > n 为真,跳转到退出块,否则进入循环体%8 = add nsw i32 %.01, 1 ; i = i + 1优化后%7 = add nuw nsw i32 %.01, 1 ; i = i + 1循环变量i从2开始且递增,因此它永远不会发生无符号整数溢出。 若我们使用-O2级别的优化,命令clang -S -emit-llvm -O2 factorial.cpp -o factorial_O2.ll 注意到 编译器引入了
注意到 编译器引入了<4*i32i>向量类型,并使用了相应的向量指令来对循环计算向量化,充分利用了现代CPU的SIMD(单指令,多数据流)处理单元。一次性完成4次乘法。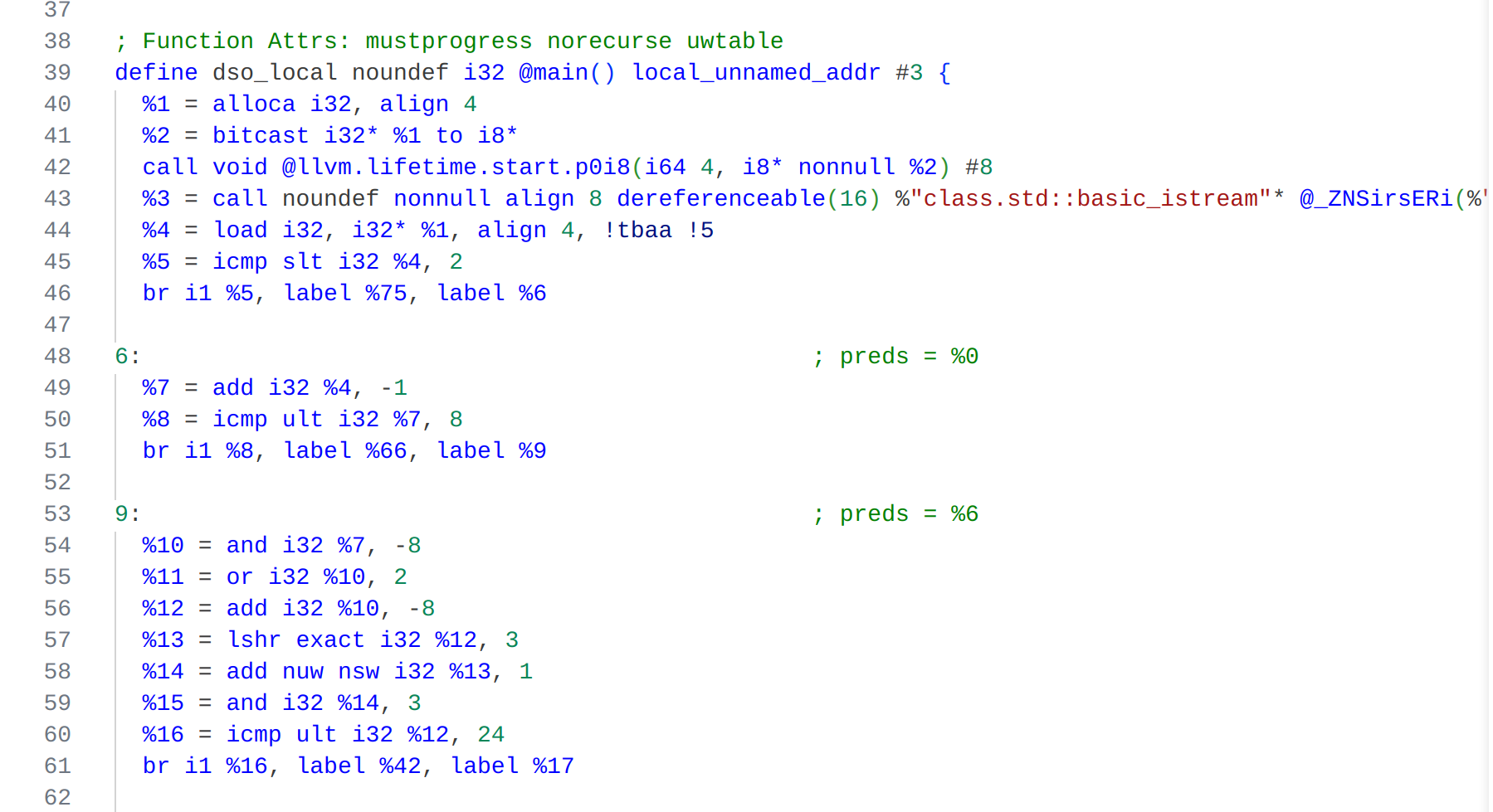
; 优化后的复杂控制流:
br i1 %5, label %75, label %6 ; n < 2 直接返回1 br i1 %8, label %66, label %9 ; 小循环处理 br i1 %16, label %42, label %17 ; 向量化处理
循环根据n的大小选择不同的计算分支:若n<2,直接返回1;若n较小,使用标量循环;若n大于9时,使用向量化循环。
目标代码生成
在这一阶段,中间代码转换为目标代码。
gcc factorial.ii -S -o factorial.S
使用这一条命令生成两个文件,一个是纯汇编文件后缀为.s,另一个是包含预处理指令的汇编文件。
使用g++驱动只生成一个.S文件。
汇编
汇编器将factorial.s翻译成机器语言指令,把这些指令打包成一种叫做可重定位目标程序的格式,并把结果保存在factorial.o目标文件中。该文件是一个二进制文件,直接打开会看到一堆乱码。其中包含的内容有:机器指令、节的布局(代码与数据分配到不同节)、符号表(定义的与引用的符号)、重定位信息和调试信息。
详细分析并阐述汇编器处理的结果以及汇编器的具体功能分析
g++ factorial.S -c -o factorial.o
使用命令查看反汇编代码
objdump -d factorial.o > factorial-anti-obj.S
得到的代码如下:
factorial.o: 文件格式 elf64-x86-64
Disassembly of section .text:
0000000000000000 <main>:
0: f3 0f 1e fa endbr64
4: 55 push %rbp
5: 48 89 e5 mov %rsp,%rbp
8: 48 83 ec 20 sub $0x20,%rsp
c: 64 48 8b 04 25 28 00 mov %fs:0x28,%rax
13: 00 00
15: 48 89 45 f8 mov %rax,-0x8(%rbp)
19: 31 c0 xor %eax,%eax
1b: 48 8d 45 ec lea -0x14(%rbp),%rax
1f: 48 89 c6 mov %rax,%rsi
22: 48 8d 05 00 00 00 00 lea 0x0(%rip),%rax # 29 <main+0x29>
29: 48 89 c7 mov %rax,%rdi
2c: e8 00 00 00 00 call 31 <main+0x31>
31: c7 45 f0 02 00 00 00 movl $0x2,-0x10(%rbp)
38: c7 45 f4 01 00 00 00 movl $0x1,-0xc(%rbp)
3f: eb 0e jmp 4f <main+0x4f>
41: 8b 45 f4 mov -0xc(%rbp),%eax
44: 0f af 45 f0 imul -0x10(%rbp),%eax
48: 89 45 f4 mov %eax,-0xc(%rbp)
4b: 83 45 f0 01 addl $0x1,-0x10(%rbp)
4f: 8b 45 ec mov -0x14(%rbp),%eax
52: 39 45 f0 cmp %eax,-0x10(%rbp)
55: 7e ea jle 41 <main+0x41>
57: 8b 45 f4 mov -0xc(%rbp),%eax
5a: 89 c6 mov %eax,%esi
5c: 48 8d 05 00 00 00 00 lea 0x0(%rip),%rax # 63 <main+0x63>
63: 48 89 c7 mov %rax,%rdi
66: e8 00 00 00 00 call 6b <main+0x6b>
6b: 48 8b 15 00 00 00 00 mov 0x0(%rip),%rdx # 72 <main+0x72>
72: 48 89 d6 mov %rdx,%rsi
75: 48 89 c7 mov %rax,%rdi
78: e8 00 00 00 00 call 7d <main+0x7d>
7d: b8 00 00 00 00 mov $0x0,%eax
82: 48 8b 55 f8 mov -0x8(%rbp),%rdx
86: 64 48 2b 14 25 28 00 sub %fs:0x28,%rdx
8d: 00 00
8f: 74 05 je 96 <main+0x96>
91: e8 00 00 00 00 call 96 <main+0x96>
96: c9 leave
97: c3 ret
0000000000000098 <_Z41__static_initialization_and_destruction_0ii>:
98: f3 0f 1e fa endbr64
9c: 55 push %rbp
9d: 48 89 e5 mov %rsp,%rbp
a0: 48 83 ec 10 sub $0x10,%rsp
a4: 89 7d fc mov %edi,-0x4(%rbp)
a7: 89 75 f8 mov %esi,-0x8(%rbp)
aa: 83 7d fc 01 cmpl $0x1,-0x4(%rbp)
ae: 75 3b jne eb <_Z41__static_initialization_and_destruction_0ii+0x53>
b0: 81 7d f8 ff ff 00 00 cmpl $0xffff,-0x8(%rbp)
b7: 75 32 jne eb <_Z41__static_initialization_and_destruction_0ii+0x53>
b9: 48 8d 05 00 00 00 00 lea 0x0(%rip),%rax # c0 <_Z41__static_initialization_and_destruction_0ii+0x28>
c0: 48 89 c7 mov %rax,%rdi
c3: e8 00 00 00 00 call c8 <_Z41__static_initialization_and_destruction_0ii+0x30>
c8: 48 8d 05 00 00 00 00 lea 0x0(%rip),%rax # cf <_Z41__static_initialization_and_destruction_0ii+0x37>
cf: 48 89 c2 mov %rax,%rdx
d2: 48 8d 05 00 00 00 00 lea 0x0(%rip),%rax # d9 <_Z41__static_initialization_and_destruction_0ii+0x41>
d9: 48 89 c6 mov %rax,%rsi
dc: 48 8b 05 00 00 00 00 mov 0x0(%rip),%rax # e3 <_Z41__static_initialization_and_destruction_0ii+0x4b>
e3: 48 89 c7 mov %rax,%rdi
e6: e8 00 00 00 00 call eb <_Z41__static_initialization_and_destruction_0ii+0x53>
eb: 90 nop
ec: c9 leave
ed: c3 ret
00000000000000ee <_GLOBAL__sub_I_main>:
ee: f3 0f 1e fa endbr64
f2: 55 push %rbp
f3: 48 89 e5 mov %rsp,%rbp
f6: be ff ff 00 00 mov $0xffff,%esi
fb: bf 01 00 00 00 mov $0x1,%edi
100: e8 93 ff ff ff call 98 <_Z41__static_initialization_and_destruction_0ii>
105: 5d pop %rbp
106: c3 ret文件的格式为elf64 x86-64.分为3个部分,首先是main函数的反汇编,其次是静态对象构造与析构函数,最后是全局构造函数。
- main函数中第一行表首先是栈的设置和保护(金丝雀1)
- 静态对象构造与析构函数用于初始化全局I/O对象
- 全局构造函数在main函数之前被调用 从中可以看出汇编器的功能有:
- 指令编码:例如
push %rbp会被汇编器编码为机器码55 - 地址分配与管理:每条指令分配相对地址,
push %rbp地址为4。对于汇编代码中的各种标签(如 jmp .L2)会计算出相对地址然后嵌入到机器码当中。 - 处理汇编伪操作与节信息:
.text、.section、.globl、.type、.size、.init_array、.comm等被转成相应的节/表项,放入目标文件(.o)的节头表。告诉汇编器如何组织生成目标文件。使用命令objdump -h factorial.o - 符号解析:汇编器在处理
factorial.s文件时,会识别符号并放入符号表。 - 重定位处理:对于外部符号引用
call _ZNSirsERi@PLT
leaq _ZSt4cout(%rip), %rax
由于汇编器无法解析其地址,用 00 00 00 00 来填充,并且在目标文件中创建重定位的条目: 对于call 31,生成一个R_X86_64_PLT32类型的重定位; 对于lea 0x0(%rip),生成一个R_X86_64_PC32类型的重定位。使用命令objdump -r factorial.o可以查看相关信息。
2c: e8 00 00 00 00 call 31 <main+0x31>
22: 48 8d 05 00 00 00 00 lea 0x0(%rip),%rax
使用命令查看符号表 objdump -t factorial.o。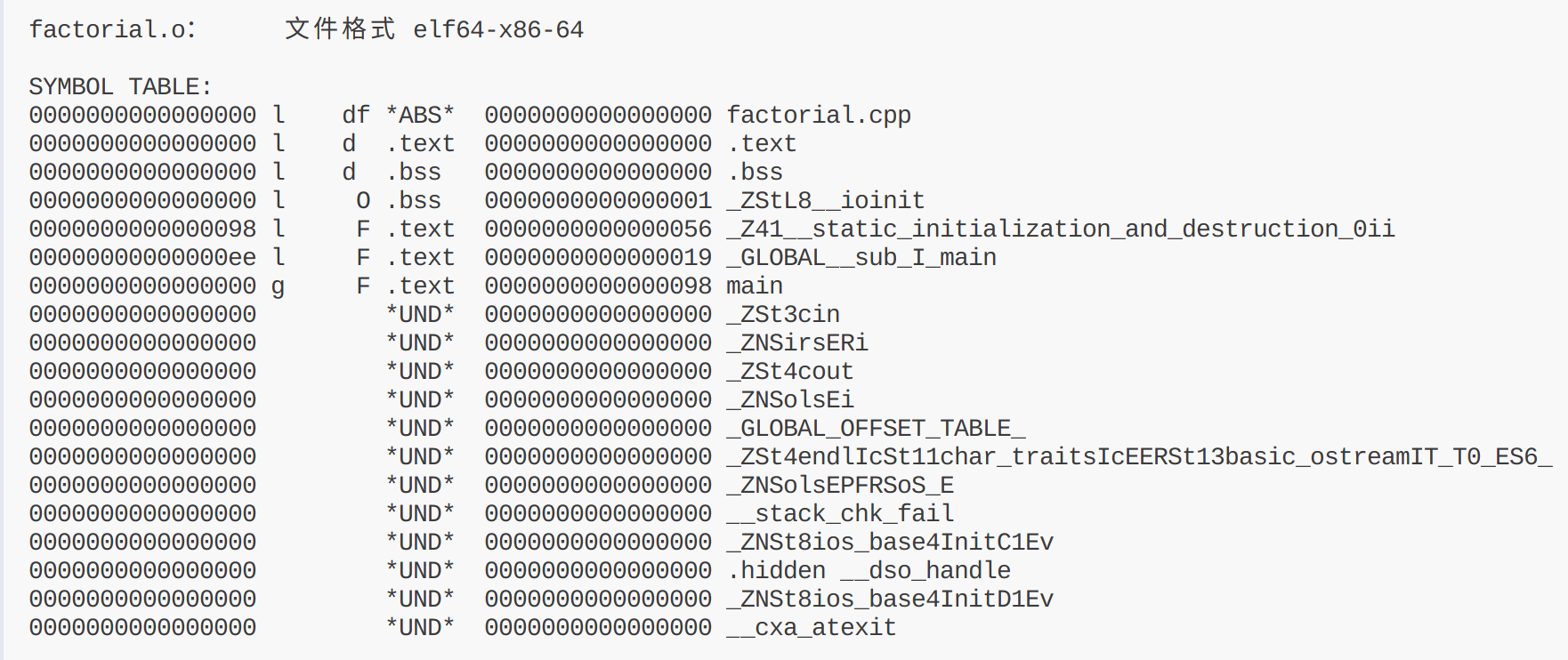
符号表的第一列表示地址,第二列表示作用域是局部还是全局,第三列表示符号类型(df:调试文件,d:节,O:对象;F:函数),第四列表示节的类型,第五列表示大小(字节为单位),第六列表示符号名称。 从中可以得知内存的布局:
.text 节(代码段)
+0x000:main函数
+0x098:静态初始化函数
+0x0ee:全局构造函数
.bss 节(未初始化数据段)
+0x000:_ZStl8_ioinit上面的许多未定义符号(I/O函数和对象)在当前目标文件中被引用,但定义在其它文件中需要在下一个阶段链接时从其他库(c++标准库)中解析。(使用-C选项可以使得c++相关符号名称易读。)
链接
链接器的工作是将多个可重定位机器码文件组合成单一程序,解决外部引用(变量、函数),输出符号表
使用命令g++ -O0 -o factorial factorial.o
使用命令objdump -d factorial > factorial-anti-exe.S 进行反汇编,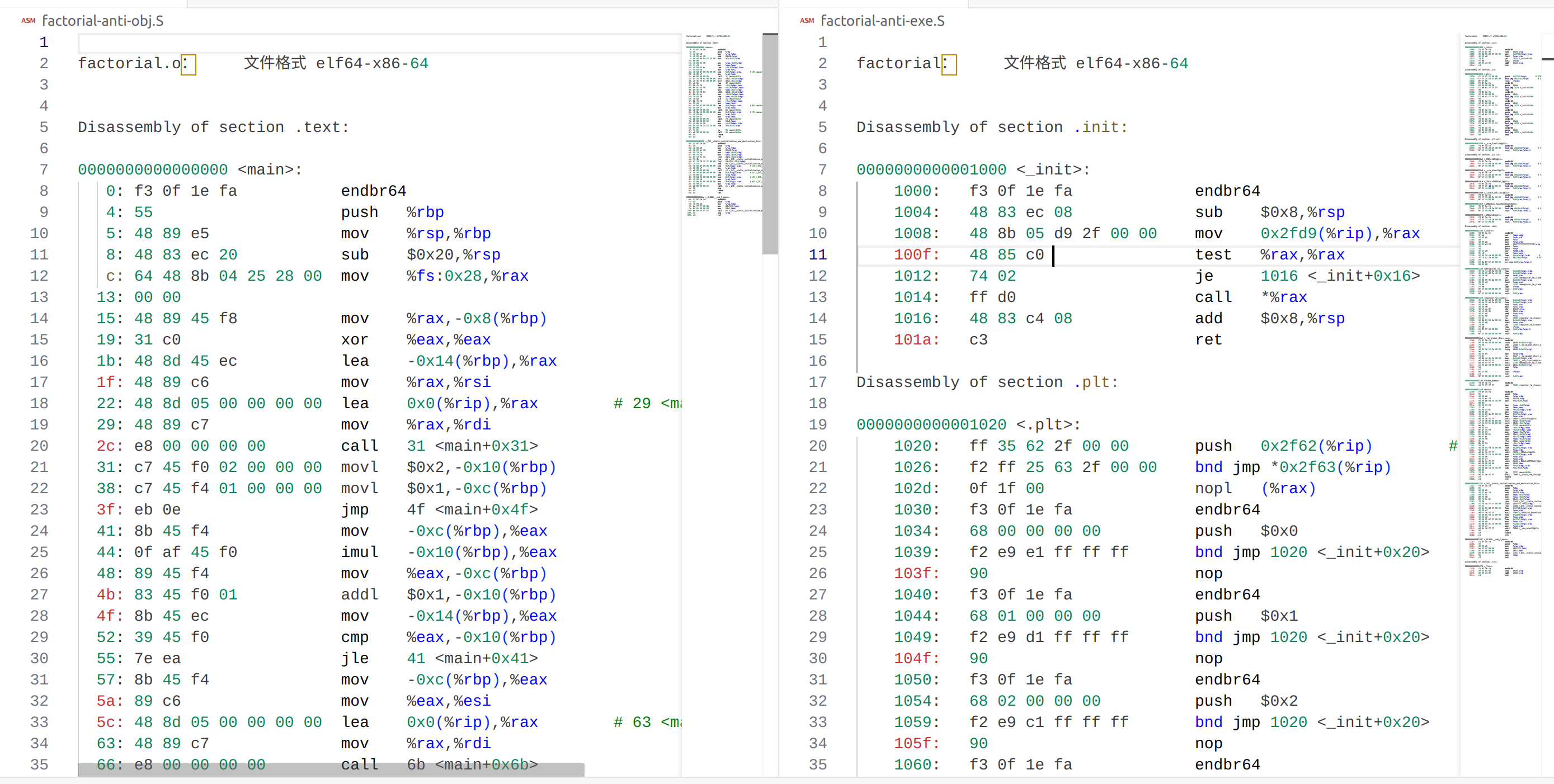 与之前生成的结果比较,发现exe包含所有的节从开始的init到结束的fini,而目标文件只有text的节。同时在上一阶段没有填充的地址也赋值了。代码的地址也从0x0000变成了从0x1000开始
与之前生成的结果比较,发现exe包含所有的节从开始的init到结束的fini,而目标文件只有text的节。同时在上一阶段没有填充的地址也赋值了。代码的地址也从0x0000变成了从0x1000开始
Footnotes
-
来源于英国矿井工人用来探查井下气体是否有毒的金丝雀笼子。工人们每次下井都会带上一只金丝雀。如果井下的气体有毒,金丝雀由于对毒性敏感就会停止鸣叫甚至死亡,从而使工人们得到预警。https://ctf-wiki.org/pwn/linux/user-mode/mitigation/canary/ ↩